Em um projeto de RTM (Route-to-Market) para um importante cliente da indústria de bebidas, o grande desafio foi traduzir as necessidades dos consumidores finais em um atendimento assertivo, que levasse em conta as diversas variáveis que os caracterizavam desde diversos aspectos:
- Geografia: o cliente atende a todos os estados do Brasil. Lugares caracterizados por muitas cidades interiorizadas, de baixo Dropsize do produto, baixa densidade demográfica e baixa renda. Como oferecer um nível de serviço com atendimento presencial, quando a demanda ainda é menor do que a receita trazida por esses consumidores finais?
- Volume: diferentes padrões de consumo da linha de produtos do cliente e relativa dificuldade nas vendas dos produtos classe A, principalmente devido à predominância de uma baixa renda no nordeste brasileiro. Como incentivar o consumo de um tipo de produto mais caro, em uma região onde a maioria prefere consumir os produtos locais, em virtude de um menor preço?
- Padrão de consumo: mudança gradativa e crescente da consciência alimentar do consumidor final, que aos poucos deixa de ingerir bebidas açucaradas e procura substituir por produtos com uma proposta mais saudável e “natural”. A questão é que esses tipos de produtos custam mais caro, e o perfil do consumidor na região atendida pelo cliente, muitas vezes não está disposto a comprá-los o que acaba se resumindo em perda de valor vs. produtos da concorrência, mais baratos.
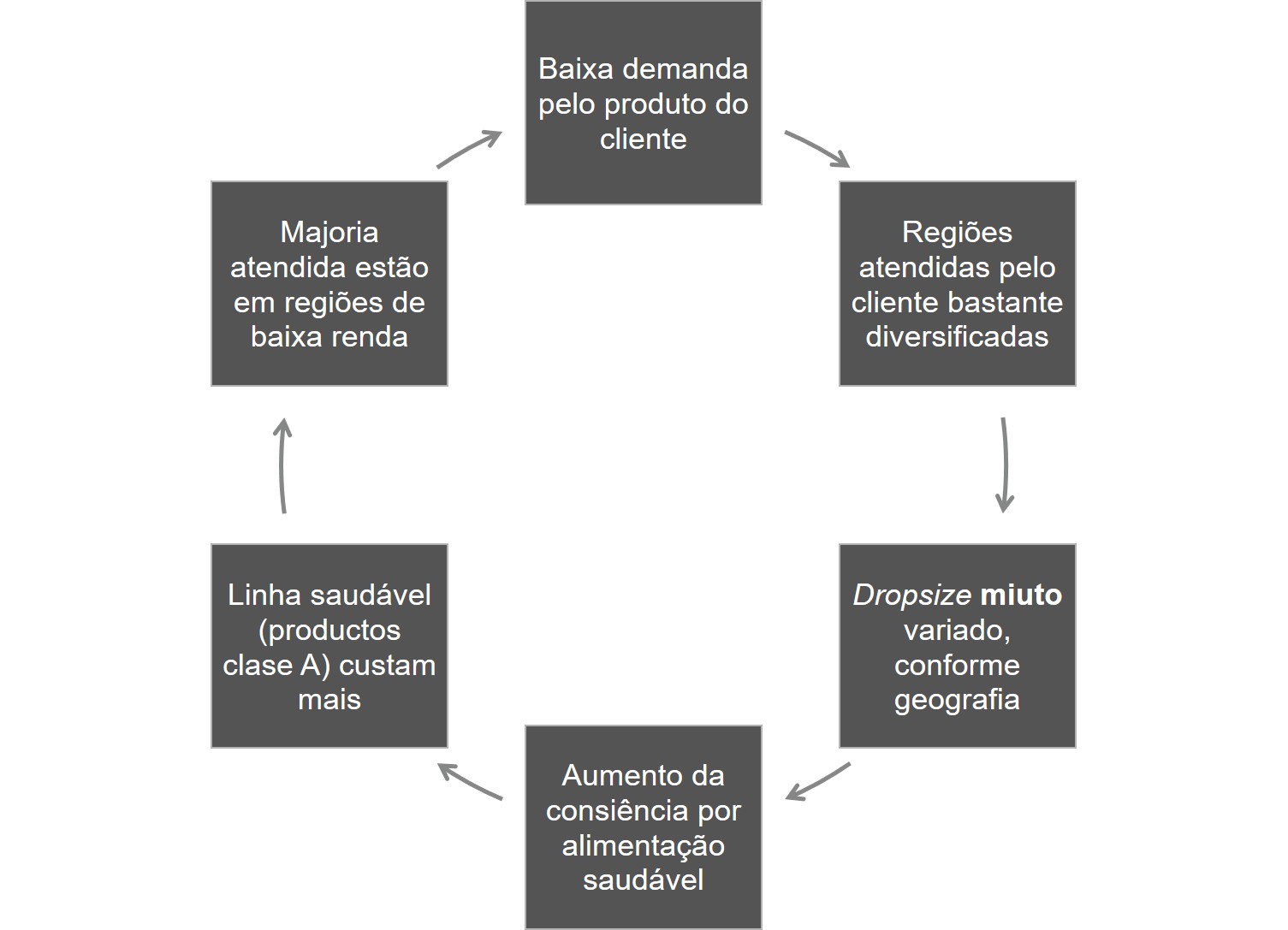
Figura 1 – Esquemático em looping da situação apresentada.
Diante dessa problemática, a Sintec elaborou uma segmentação de clientes e de território que resultou em macro modelos, que buscam ofertar níveis de atenção específicos a cada grupo conforme as possibilidades de captura de valor e desenvolvimento. Dentro de cada modelo foram detalhadas as particularidades da oferta de serviço, potencializando alguns grupos e mantendo o nível em outros.
Metodologia de Segmentação de Clientes utilizada
No processo de definição dos macro modelos, os fatores que retroalimentaram a segmentação foram:
- Classificação em Clientes Modernos (Modern-Trade-Market Driven) ou de Mercado Aberto (Tradicional ou pequeno varejo). Isso, apenas para separar clientes chaves dos clientes de rota dadas as diferentes dinâmicas de negociação.
- Caso fosse classificado em Cliente Moderno, seguia uma segunda classificação, entre Cliente Estratégico ou Cliente Relevante, conforme a representatividade desses clientes no percentual acumulado de volume (Pareto simples)
- Caso fosse classificado como Cliente Mercado Aberto, ele recebia três outras classificações:
- Volume Semanal: utilizando o método estatístico K-means na plataforma analítica Alteryx, foram calculados médias regionais, por tipo de consumo, clusterizando os clientes em perfis de volume Muito Alto, Alto, Médio, Baixo e Baixíssimo.
- Share & Entorno: a informação do share dos produtos do cliente no ponto de venda foi associada à informação do entorno. Esta, por sua vez, traz consigo informações da região próxima ao ponto de venda onde o produto do cliente será comercializado, tais como quantidade de pontos de comércio que movimentem o consumo (escolas, terminais rodoviários, hospitais etc.); quantidade de pessoas que residem nas proximidades e quantidade de pessoas que transitam pelo local. Dessa forma, as classificações resultantes foram:
- Alto Share
- Baixo Share & Alto Entorno
- Baixo Share & Baixo Entorno
- Porte do ponto de venda: recebe uma classificação conforme tamanho do ponto de venda dentro da sua categoria de perfil de consumo, se de consumo futuro ou consumo imediato.
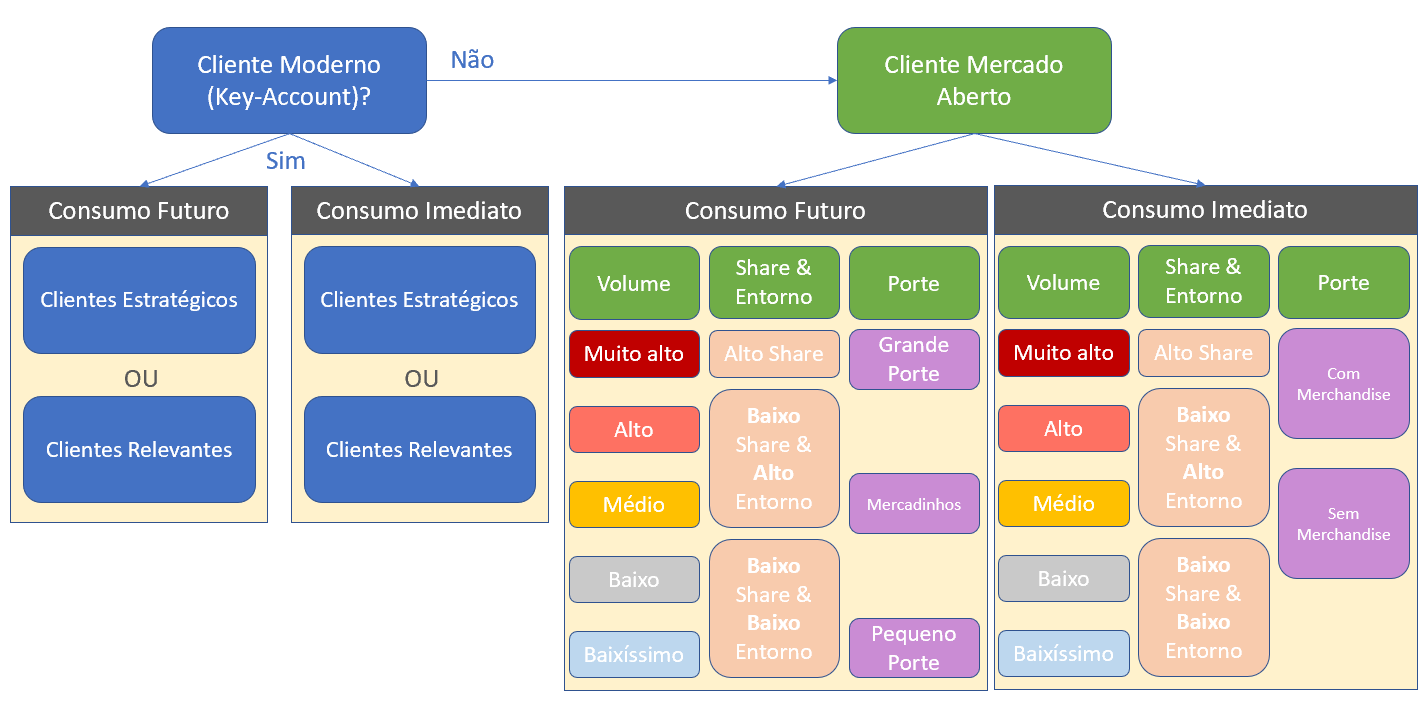
Figura 2 – Esquema ilustrativo da lógica de classificação dos clientes.
Resultados
A robustez e embasamento matemático e estatístico que a metodologia de clusterização k-means conferiu aos modelos, contribuiu para propor níveis de serviço mais aderentes ao perfil dos clientes atendidos. Cada um dos modelos corresponde a um grupo de clientes que possuem comportamentos de consumo semelhantes, geografias com características similares e porte de comercialização equivalentes.

Figura 3 – Esquema ilustrativo do processo iterativo de clustering feito pelo algoritmo K-means. Na sequência, amostra de dados recebem uma média que melhor representa os datos e os divide em K clusters. Essas médias são revisitadas e ajustadas em um processo iterativo, até que não se altere e chegue-se à definição do centróide e cluster.
Considerações Finais: trabalhando em segmentações envolvendo mais de uma variável
A maior dificuldade encontrada foi estabelecer níveis de serviço adequados para clientes com características tão divergentes entre si. A região Nordeste, atendida pelo cliente, compreende por si só uma variedade de perfis econômicos, geográficos e de consumo. Trata-se de um território formado por muitas cidades interiorizadas, de baixa população, sugerindo menor consumo, quando comparadas às capitais. Estas também podem apresentar comportamentos muito distintos entre si, algumas com seus produtos regionalizados muito ligados à cultura do local, ou com forte consumo sazonal, dependentes do turismo.
A baixa densidade demográfica representa a complexidade na distribuição e acesso aos locais; a baixa renda pode ser um forte indicativo de baixo dropsize na entrega, de produtos muitas vezes mais baratos (com menor margem de lucro); a baixa ou alta população serve de indicador do tamanho do mercado. Mas nenhum desses dados sozinhos pode oferecer uma boa noção da região atendida e como ela se comporta. Somente unindo esses indicadores econômicos é que se obtem uma melhor visão da realidade de mercado nesse território, e estaremos aptos a preparar uma segmentação de clientes e/ou territorial.
O K-means pode ser usado nesse tipo de situação, quando se deseja distribuir dados em clusters, a fim de se obter comportamentos semelhantes, através de números. Esses clusters serão representados por uma média e serão formados por pontos (ou dados) que carregam traços semelhantes entre si. Por ser uma metodologia estatística, é importante que alguns cuidados e tratamento dos dados sejam aplicados antes. Mas se realizado o cálculo do K-means em uma plataforma analítica, como Alteryx ou KNIME, o procedimento fica mais rápido e automatizado.
